The Associated Press (AP) recently announced a semantic markup standard they’d like to see adopted online for news articles – the “hNews Microformat“. The proposed microformat was announced simultaneously with their declaration of a news registry system to facilitate protection and paid licensing arrangements for quoting and using news article material. While the overall announcement and news registry system was widely ridiculed in the blogosphere (in part because of a confusingly inaccurate description which stated that the microformat would serve as a “wrapper” for news articles, and the overall business model and protection scheme seems both naively optimistic and out-of-touch with copyright “fair use” standards and actual technological constraints), but the hNews microformat part itself could potentially gain some traction.
So, if you’re an online marketer of a site which publishes large amounts of articles and news stories, is the hNews microformat worth adopting to improve your online optimizations?
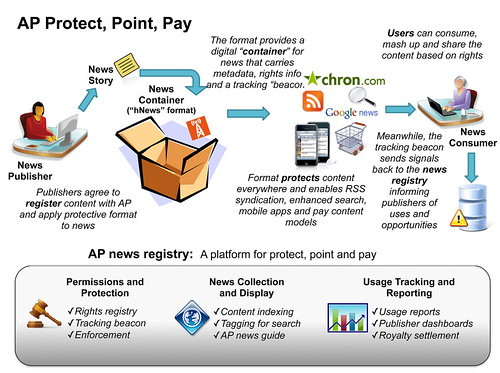
(AP's Diagram Illustrating "Protect, Point & Pay" System & hNews Microformat)
I’ve long been a proponent of incorporating microformats within webpages as a component of overall good usability and potentially valuable formatting for search engine optimization purposes. Microformats can provide some additional, enhanced usability for advanced users who are using devices which can read the information and store it for future use, and they can potentially improve search engines’ ability to understand the content within webpages which could lend a marginal increment more SEO value.
Both Yahoo! and Google have been sending signals for the past few years that they consider some of the microformats to be potentially useful as well. They’ve both marked up their own local search results with hCard microformatting for end users’ benefit, and they’re both starting to make use of microformatting to give certain types of data special treatment. In the case of Google, they announced that they’d begin displaying some microformat data with slightly different listing layouts in the search results, a treatment that they’ve dubbed “Rich Snippets”. And, they say they’ll be rolling out more treatments based on microformats in the future.
With this background in mind, it’s not surprising that the AP has jumped on the microformats bandwagon, but it also appears that they’re trying to influence the development of them where news articles are concerned, with a major agenda in mind. They wish to include some sort of webbug in each news story’s markup, so that publishers of the content can be tracked more easily by them – it will be clearer when sites are reprinting news stories, and how frequently those stories are visited and viewed by consumers online.
Other portions of the hNews microformat appear to be more useful from both a search engine viewpoint and publisher site aspect. Labelling of items including keyword tags, headlines, main content, geographic locations and including author’s vcard info all appear to be valuable standards.
(I could really criticize their “geo” tagging of the articles as quite inadequate, though. Merely adding a longitude and latitude to an article seems quite short-sighted, because there needs to be further definition of what is being geotagged. If an article is about multiple locations, it would be ideal to label each geotag to tell what item is being located. Further, it would be ideal to label the article with an assumption of the geographic region that the article should be expected to appeal to. Is it mainly of interest to people within a particular city, state/province, region, nation, or is it of international interest? Still, having some geotag is better than nothing.)
For any marketers out there considering adopting the hNews Microformat standard, I’d advise waiting until the dust settles on this one. Other microformats developed perhaps more objectively, and there’s a lot of distrust and disaffection with the heavy news industry influence that is involved in this proposed standard. Currently, I’m not convinced that it will be widely enough accepted to become valuable for use. While having AP partners all adopting the standard may be sufficient enough to reach a tipping point where many other sites and companies will make use of hNews, Google’s public response to it was unusually cold-sounding.
Blogger/reporter Matthew Goldstein quotes Google’s response on the matter: “Google welcomes all ideas for how publishers and search engines can better communicate about their content. We have had discussions with the Associated Press, as well as other publishers and organizations, about various formats for news. We look forward to continuing the conversation.” While sounding expectably neutral and noncommittal, Google is also stating that this has not been widely-accepted by everyone, even within the news industry itself. This in combination with widespread skepticism within the developer/microformat community and blogosphere signal that hNews may have a very long way to go before it becomes something worthwhile for optimizing articles on publisher sites.
So, for now I advise avoiding this proposed standard, sit back and see how the dust settles. If you’re already syndicating content via RSS and Atom feeds, then you’re already distributing your content in a manner that’s easily absorbable and readable by search engines.



 We’ve got some exciting news here at the SEMClubhouse. Another great SEO mind has joined not just the clubhouse, but the
We’ve got some exciting news here at the SEMClubhouse. Another great SEO mind has joined not just the clubhouse, but the 
