Finding dollars a little tighter this year is a common problem so learning new ways to stretch marketing dollars is more important than ever. Improving your PPC landing pages so they convert better is one dynamite way to improve your ROI.

Stretch your marketing dollars by optimizing your landing pages
With that in mind, here are a few tips for making your landing pages more effective. The goal here is to make your landing pages more persuasive, focused, and complete, and to provide the necessary testing feedback to measure the success of your efforts.
1. Make your the landing page Mobile Friendly. The number of mobile searches surpasses desktop searches for many industries and demographics. If you are spending money to send people to a page, the page needs to render well.
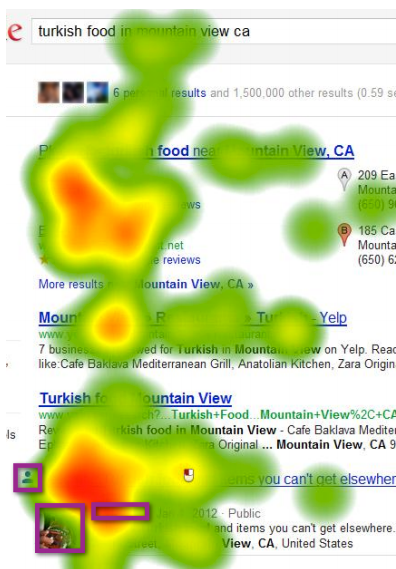
2. Include a call to action and place it ABOVE the fold. Your landing page can be long or short – you’ll need to test the page to know which works best for you, but always include a call to action above the fold.
3. Make the call to action look like a button and make it larger and brighter than you think you need. Text links have their place but they don’t draw the eye as much as a brightly colored button call to action.
4. It is still benefits not features. Those of us in marketing hear that expression all the time, but it is amazing how many pages include content that is all about features. Don’t tell me the statistics on a product; tell me how my life will be improved if I buy it. Remember it’s emotions that really motivate us to buy. We like to have the logic to explain to our friends why we purchased something, but most of us really buy a particular item because it fulfilled an emotional need.
Focus -You know the keywords and ad text that lead to the customer clicking on your ad. Now, make sure that you maintain that focus and lead visitors to the next step in purchasing on your site. Maintaining continuity by providing the proper focus to the landing page will help to keep those visitors on track.
5. Continuity between ad and the landing page is a must.. Inconsistent messaging can confuse a visitor. If they click on an ad with a certain value proposition, then the landing page should reinforce the appeal mentioned in the ad copy.
6. Remove unnecessary noise and clutter on the page. Too many bright graphics and excessive bold text can distract visitors. Links to other offers can de-rail customers from their purchase mission. When presented with too many options, visitors often get confused and leave a site or if distracted, they might totally forget why they entered your site in the first place.
7. Ensure your customer contact loop is working. Can the potential customer coming to your page contact you easily? Is the submission form working? How reliable is the VOIP number you are using? If a phone call is the preferred method for customers to contact you, is the phone number present on the page and easy to find? If you are using a phone number on the landing page, do you have a method to track offline conversions? If not, you have a big hole in your analytics.
8. Include Trust factors on the landing page. Specialized badges, Better Business and Chamber of Commerce memberships, testimonials, and a professional looking web site all convey confidence to the visitor that your site is trustworthy. Use trust factors on the page whenever possible.
9. Keep your SSL certificates up to date. Nothing increases the bounce rate on your landing page like serving potential customers an expired SSL certificate notice. Secure Sockets Layer (SSL) certificates are used by ecommerce sites to encrypt sensitive information during online transactions. If expired, the visitor is served up a frightening notice. Most visitors don’t know what the notice means and leave your page feeling very uncomfortable about doing business with you.
10. Test your landing page in different browsers. Designers often build landing pages in a hurry without the extensive testing program normally included in a site redesign. This inattention to detail can cause browser compatibility issues to sneak into your landing pages. For optimum user experience, view the landing page in Edge, Chrome, Firefox, Opera, and Safari. A free tool that lets you view how pages render on different browsers is located at BrowserShots.org.
Testing pages under different browsers is an extra step and takes time, but poorly rendering pages make a bad impression and can cost you sales.
11. Make sure analytics is installed correctly and capturing true performance. Analytics is only as good as the data you feed it. If you forget the analytics JavaScript on a landing page or include the JavaScript but accidentally enter a typo while dropping it on the page, the story your analytics is telling you may be inaccurate. We have seen both of these occur on big brand sites on more than one occasion. Test that your analytics is capturing conversions correctly or you may base your marketing decisions on incorrect information.
12. Conduct a usability test on the landing page with a live person from the target audience. Many times we put all the best practices to work and find pages still aren’t converting like we expect. One of the simplest ways to figure out what is going wrong is to pick someone from the target demographic and have them sit down with you and do an old fashion usability test.
Give the usability tester a scenario and a mission to buy a product from your website. Tell them to start with the ad and then arrive on the landing page. Have them talk out loud about how they perceive the page.
You can’t have an ego when you’re doing usability testing. Prepare for brutal criticism because you may find the copy you thought was so compelling is considered drivel by the tester. Or the tester may sit staring at your page lost about where to go next because the link you thought was so obvious is invisible to them. Usability testing reveals problems that your analytics may be hinting at, but don’t definitively tell you.
13. Use multivariate testing to test options on the page. You are never done fine tuning your landing pages. As you put out new pages, learn what worked on earlier pages but continue to try new things too. In this competitive market, getting even another percentage better can make the difference between success and failure. Google Website Optimizer is a free tool that allows the webmaster to perform multivariate testing. Software that did this used to be very expensive. Google provides the tool without cost and has made it straightforward to use.
If you put all these tips and techniques into play, I am confident that you will improve the overall effectiveness and convertibility of your landing pages and will help to make you paid search campaigns more profitable.
If you need help with your PPC marketing and landing page optimization, feel free to give KeyRelevance a call at 972-429-1222.
 The Chromium developers recently committed a new “Never-Slow Mode” set of changes to the prototype Chromium codebase in order to test out some new features designed to speed the rendering of web pages.
The Chromium developers recently committed a new “Never-Slow Mode” set of changes to the prototype Chromium codebase in order to test out some new features designed to speed the rendering of web pages.